Web Performance: быстрый, отзывчивый, стабильный в 2025
Web Performance - это такая штука, про которую постоянно говорят как об очень важной для современного веба! Что это едва ли не ключевой фактор для пользовательского опыта (UX), конверсий, SEO, успешности в Интернете. Начинаем каждый год со статьи “Новые челленджи и почему быстрые сайты победят в 20xx году”.
Но когда дело доходит до реализации, такая задача в бэклоге часто не находит должного приоритета. Не находит по двум причинам, так как встают два вопроса:
1.А правда важно? - пользователи не жалуются, у меня тоже все быстро открывается. Да и наши внутренние исследования не показали явной корреляции метрик с позициями в поисковой выдаче. Что еще за CLS ноль и четыре, и что?
2.А оно того стоит? - метрик слишком много, они непонятные, еще и новые постоянно придумываются, а инструменты сложные и дорогие. Может, лучше потратим ресурсы на продуктовые фичи?
Эта статья в формате руководства рассказывает, как можно ответить на эти вопросы в 2025 и выстроить сбалансированный процесс вокруг веб-производительности. А баланс, как всегда, между инженерными решениями и ожиданиями бизнеса.
У нас не интернет магазин
Исследования проводили и проводят гиганты Интернета, такие как Amazon, Google или Walmart. Уже стали штампами выводы, что каждые 100 мс задержки обходятся в 1% конверсий, что увеличение времени рендера страницы приводит к потере запросов, что половина пользователей на третьей секунде вообще страницу покидают. Звучит страшно, но почему то - не страшно.
Не страшно, потому что эти исследования где-то там далеко, для гигантских торговых площадок. Эти выводы слабо применимы к нашему рыболовному магазину на специализированную аудиторию. Или у нас своя социальная сеть (где говорят исключительно правду, даже в рекламе) - ни разу не магазин. Или вовсе наше приложение - это веб-аналог фотошопа - нормально, что долго загружается. Действительно, неочевидно, как измерить вклад от возможных оптимизаций производительности на конкретном бизнесе?
Если измерить ROI (Return On Investment) трудно, то в условиях конкурентного рынка потерять любое из возможных преимуществ - точно нежелательно. Поэтому можно задать другой вопрос: а как дела обстоят у наших прямых конкурентов? Может, пользователи не жалуются, потому что просто уходят к ним. И тут уже не важно: речь про фото-редактор или правдивую социальную сеть.
Конкурентный бенчмаркинг на коленке
Сравнение своего бизнеса в Интернете с конкурентами - это большое и важное дело. Даже в узком контексте метрик производительности есть целые сервисы с готовыми решениями (например, SpeedCurve). Но чтобы просто получить общее представление, нам это дорого и не понятно.
Где бы взять данные хотя бы недорого? Google тут уже все сделал - это Chrome UX Report (или CrUX) - огромный открытый датасет про то, как реальные пользователи браузера Chrome взаимодействуют с популярными сайтами. Все нужные (для затравки) метрики производительности там есть.
Есть целый набор CrUX Tools для доступа к данным от Google (а также на парсинге, конечно же, зарабатывают и сторонние компании). Через разные инструменты можно получить доступ по домену (origin) или отдельным страницам, по разным регионам и типу клиентского устройства, за разный период времени.
Самый простой способ для бенчмаркинга - это CrUX Dashboard, который без регистрации и смс предоставляет нужные данные по всему домену и по месяцам. Достаточно указать нужный домен, и будет получен дашборд.

CrUX Dashboard на январь 2025
Тут мы попадаем на какие-то три метрики под заглавием Core Web Vitals. Сейчас нас интересует только то, что какой-то процент измерений по метрикам - зеленый (Good), а какой-то - оранжевый (Needs Improvement) или даже красный (Poor).
Берем домены своих конкурентов и делаем такие же дашборды. Отступлением нужно сказать, что определение самих конкурентов - за рамками настоящей статьи. Дальше сравниваем обилие не-зеленого (можно и через Excel) и готовим:
▪ЕСЛИ вы - менеджер, ТО задачу на озеленение
▪ЕСЛИ вы - инженер, ТО презентацию на тему “Они - зеленые! Мы - красные!”
Мотивация - сделать не хуже, чем у конкурентов - это уже хорошая мотивация. Если тут удалось достичь консенсуса, то процесс запускается.
Однако уже на этом месте стоит обратить внимание на красное. Вне зависимости от результатов конкурентного бенчмаркинга все, что попадает в зону Poor, стоит трактовать как “пользователи недовольные производительностью”. Жалоб может не быть, потому что написать в тех поддержку - это еще потратить время, проще в этот раз стерпеть или уже закрыть вкладку.
Не разовая акция
Если первый бенчмаркинг показал хорошие результаты или какие-то работы уже были сделаны для улучшений, важно: ситуация легко может измениться. Для быстрой ретроспективы с помощью инструмента CrUX Vis можно получить картинку по историческим данным за последние 25 недель и наблюдать изменения.

СrUX Vis на январь 2025,
экспериментальный инструмент визуализации CrUX History данных
Метрики производительности имеют свойство со временем ухудшаться, если не предпринимать какие-то меры, причины следующие:
▪Рост сложности и объема приложения
▪Накопление техдолга и зависимость от сторонних ресурсов
▪Внешние факторы: изменения в браузерах, сетях и клиентских устройствах
Поэтому Web Performance - это не что-то, что можно один раз починить и забыть. Производительность требует мониторинга. А мониторинг в продакшне - это непрерывный процесс.
Постановка задачи
Итак, работы над Web Performance определены как важные. Пора поставить задачу, но с чего начать? Пока понятным требованием можно назвать то, что не хочется тратить большие ресурсы и нет желания строить вокруг метрик техно-культ. Тогда, с оглядкой на это требование, запишем остальные:
Во-первых, нужен перечень метрик и их граничные значения. Метрики должны быть понятными не только инженерам, а список не должен быть большим.
Во-вторых, важно понять, как и откуда эти метрики снимать. Желательно, поближе к пользователям, чем-то удобным и недорогим. Еще бы иметь возможность тестировать заранее, не дожидаясь проблем на продакшне.
В-третьих, результатом должен быть выстроенный процесс. От сбора данных и их анализа до алертов и тикетов в бэклоге на устранение проблем. Процесс должен быть прозрачным для всех.
Жизненно важные метрики
На первый взгляд может показаться, что метрик производительности вагон и маленькая тележка. И это действительно так, и это действительно не на пустом месте.

Некоторые метрики производительности на 2025 год
Чтобы начать разбираться, нужно понять, а кто выдвигает требования и определяет важно или не важно? А источников требований всего два:
1.UX - каждое приложение стремится доставить хороший, а иногда и уникальный, пользовательский опыт. Качественный UX напрямую влияет на конверсии, а производительность - его неотъемлемая часть.
2.Search Bot - поскольку речь про веб-приложения, рекомендации от поисковиков игнорировать нельзя. Несмотря на закрытость алгоритмов ранжирования и, возможно, недоверие к ним, не хочется здесь прогадать.
В идеале начать работы по производительности стоит с опроса UX и SEO специалистов в компании. У этих ребят точно будут полезные инсайды.
Так получилось, что Google еще в 2020 озадачился проблемой обилия метрик, и метрик, как правило, сугубо технических. И появилась инициатива Web Vitals, которая призвана создать единый набор рекомендаций с акцентом на достижение хорошего именно пользовательского опыта. Тут объединяются оба источника требований: Google говорит про UX и он же алгоритмы свои подкручивает.
Коротко, предлагаются три ключевых показателя, отвечающих за три различных аспекта пользовательского опыта:
▪Largest Contentful Paint (LCP) - измеряет производительность загрузки
▪Interaction to Next Paint (INP) - измеряет интерактивность элементов
▪Cumulative Layout Shift (CLS) - измеряет визуальную стабильность
Там же есть рекомендации по граничным значениям. Собственно, именно эти три метрики и их трешхолды мы видим на дашбордах CrUX.
Предполагалось, что список будет обновляться. Но за 4 года разве что INP появился на смену FID (First Input Delay), так как по части интерактивности очевидно недостаточно измерять только первый пользовательский ввод. Ну еще улучшили алгоритмы расчета CLS.
Помимо ключевых жизненно важных (Core Web Vitals) предлагаются дополнительные жизненно важные метрики:
▪Time to First Byte (TTFB) - про загрузку, когда сервер начал байты отдавать
▪First Contentful Paint (FCP) - про загрузку, когда первый контент появляется
Эти метрики фиксируются при каждом просмотре страницы. Часть метрик (LCP, TTFB, FCP) измеряется во время загрузки - от момента запроса страницы до отображения основного контента. Другие (INP, CLS) отслеживаются на протяжении всего жизненного цикла страницы, вплоть до закрытия вкладки.
Google рекомендует (и сам так делает для CrUX) производить замеры метрик по 75-ому процентилю, чтобы быть уверенными, что 75% пользователей не страдают.
Нужно сделать отступление о поддержке. Несмотря на стремление стандартизировать Web Vitals и всеобщее признание этих метрик, полная поддержка сейчас есть только в браузерах на базе Chromium (Chrome, Edge или Opera). Является ли это проблемой, когда под 80% трафика приходится на Chromium? и этот процент растет год от года. Именно проблемой - скорее нет, так как иметь удобные метрики для оценки опыта 80% пользователей - это уже победа. Но помнить про возможный негативный опыт среди оставшихся 20% - нужно. И это общая статистика. Возможно, аудитория конкретного сайта имеет другое распределение по браузерам, и тогда без дополнительных метрик уже может не обойтись.

Поддержка Web Vitals в браузерах на 2025 год
Так или иначе, около-стандартных метрик, за которыми кроется пользовательский опыт (точнее, опыт примерно 80% пользователей) оказалось не так уж и много. Можно остановиться на них и переходить к мониторингу.
Мониторим в полях
Внедрять мониторинг можно по-разному:
1.Собирать данные от реальных пользовательских устройств
2.Симулировать сессии и запросы с разных локаций и устройств
3.Анализировать приложение на локальной среде разработки
Однако мониторинг пользовательского опыта непосредственно на пользователях уже сам по себе звучит логичней остальных вариантов (но к ним еще вернемся). Это называется Real User Monitoring (RUM). Обладает преимуществами: большой объем данных, реальная среда, гео-распределение, потом - возможность строить корреляции с конверсиями.
Несмотря на преимущества по определению, от такого мониторинга хочется также получить:
▪Метрики Web Vitals (LCP, INP, CLS, TTFB, FCP) - все понятно.
▪Группировка просмотров страниц по URL, типу устройств, локации и, желательно, кастомным меткам - чтобы видеть детализированную и сегментированную картину.
▪Иметь данные по метрикам с задержкой не более суток и хотя бы за полгода - чтобы настраивать алерты и отслеживать динамику.
▪Возможность настройки процентиля измерений и различных агрегаций.
Начать можно с того же CrUX, который доступен не только по доменам, но и для отдельных страниц (CrUX History API) и групп страниц (Google Search Console). Но для крупных проектов в контексте мониторинга все его инструменты быстро демонстрируют свои ограничения:
▪Только Chrome, и даже лишь часть пользовательских сессий.
▪Страницы для репорта должны быть публичными и достаточно популярными. Что неприменимо, если нужная страница за логином.
▪Страницы группируются по URL с вырезанием фрагмента и query-параметров, что не всегда удобно, может некорректно работать для SPA.
▪Обновление данных происходит ежемесячно или с ощутимой задержкой.
▪Сводные данные, они уже сгруппированы и как-то посчитаны за нас.
Альтернативным сценарием будут готовые сторонние решения, но, скорее всего, уже платные - это Catchpoint RUM, SpeedCurve RUM, Datadog RUM или даже Sentry RUM (тем более, если он уже используется для отлова ошибок). Они все будут предоставлять метрики Web Vitals и в большей степени удовлетворять названным требованиям. Если выбирать и покупать, то вдобавок стоит обратить внимание на следующие вещи:
▪Есть ли нормальные интеграции с уже имеющейся инфраструктурой в компании? - это Prometheus, Grafana, GitLab CI, Slack, Opsgenie и проч.
▪Насколько богатый API? можно ли получить все, что доступно в UI?
▪Полезные ли дашборды, нравится ли сам интерфейс?
▪Удобно ли настраивать бюджеты и алерты по метрикам?
Если покупать ничего не хочется или что-то не нравится, то можно взять метрики под свой контроль. Для этого Google предлагает открытую библиотеку web-vitals, которая подключается на страницы сайта и может отправлять собранные метрики производительности по текущей сессии на указанный endpoint (там их надо будет самостоятельно агрегировать и перекладывать в базы данных) или в Google Analytics (нужен продуктовый аналитик? - да нет).
Сторонние решения могут поставлять свой JS-скрипт или SDK, который работает аналогично библиотеке от Google, использует тот же API браузера (другого то нет), но проще в настройке. Таким образом, что-то подключать и настраивать на страницах сайта так или иначе придется.

Можно сделать какое-то свое решение
Что в итоге выбрать? свое делать или чужое подключать. Советом будет: стараться переиспользовать те инструменты мониторинга, которые уже есть. Если в компании активно используются Prometheus и Grafana, то стоит исследовать возможность экспорта туда же метрик производительности и средств их визуализации из внешнего сервиса. Если это не получается, то тогда задуматься о своем велосипеде или его отдельных частях.
Индекс пользовательского счастья
Даже несмотря на сведение количества жизненно важных метрик к минимуму, спустя время понимание этих аббревиатур и чисел все равно стирается, и проблема “не продается”. Вот бы одну единственную метрику, которая оценивает страдание пользователей от плохой производительности.
И такая метрика есть! точнее - стандарт. Это Apdex (Application Performance Index) - индекс, который измеряет уровень удовлетворенности пользователей производительностью системы или приложения.
Принцип работы прост. Он делит запросы (в нашем случае - просмотры страниц) на три категории:
▪Satisfied - пользователь удовлетворен производительностью
▪Tolerating - приемлемая производительность
▪Frustrated - пользователь недоволен производительностью
Далее индекс рассчитывается по формуле и возвращается дробь от 0 до 1:

Изначально Apdex задумывался на измерениях времени отклика, откуда предлагает использовать целевое значение T для Satisfied запросов и 4T для Frustrated. Но это не применимо к метрике CLS, но вместо этого для каждой метрики Web Vitals уже имеются рекомендации по хорошим и плохим значениям.
Пусть Satisfied просмотры страниц - это те, где все метрики Web Vitals находятся в зеленой зоне. Frustrated - это когда хотя бы одна из метрик красная. Все остальные - Tolerating. Тогда алгоритм подсчета Apdex отлично подходит.
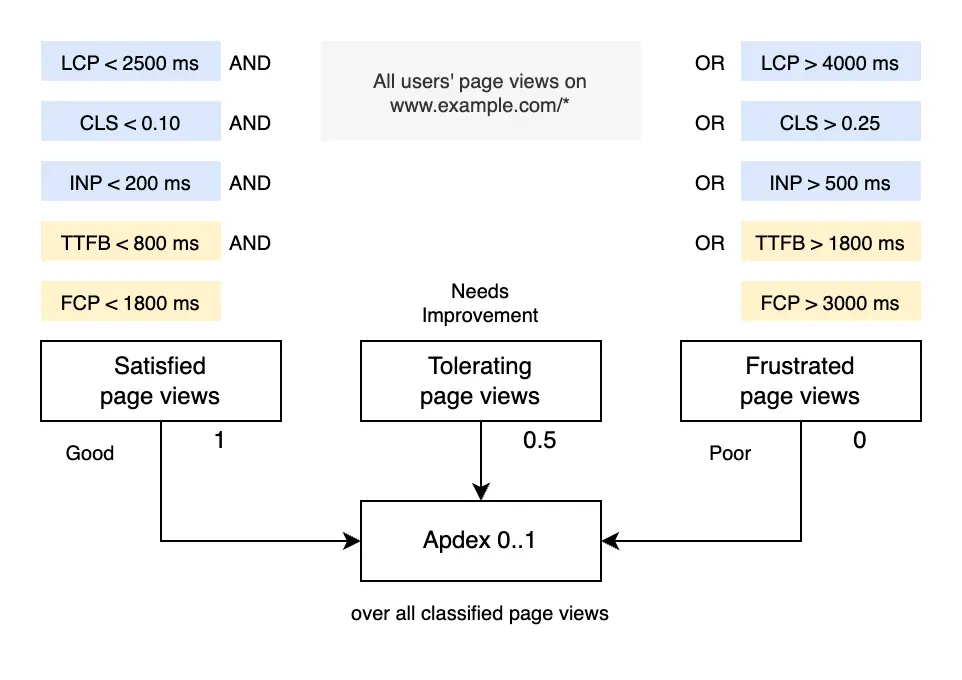
Использование Apdex для метрик Web Vitals по трешхолдам от Google
Этот алгоритм легко реализовать самостоятельно, но он также часто не обходится стороной и готовыми сервисами: Datadog Apdex или New Relic Apdex. А у кого-то так и называется - User Happiness.
Apdex удобно использовать в качестве SLI - одного из индикаторов качества сервиса - в SRE-фреймворке, основанном на концепциях SLI, SLO и SLA. Здесь Apdex в 0.8 можно трактовать как показатель, что у большинство пользователей имеют удовлетворительный или терпимый опыт.
Соответствующий SLO может быть сформулирован как требование поддерживать значение выше заданного порога (например, ≥ 0.75) на протяжении определённого окна оценки. А SLA, при необходимости, могут предусматривать компенсации в случае устойчивых и значимых нарушений SLO.
Иметь единый агрегированный и связанный с пользовательским счастьем показатель - наглядно и интуитивно понятно, чтобы начать принимать решения. Наличие такого показателя может быть одним из требований при выборе готовых решений для мониторинга.
Тестируем в лаборатории
Мониторинг на пользователях имеет свои недостатки. Во-первых, это происходит уже на продакшне, а хотелось бы не деплоить туда серьезных просадок производительности. Во-вторых, индекс счастья и ключевые метрики не дают нам детализации проблем, это только показатели.
Синтетические тесты необходимы, чтобы иметь возможность действовать превентивно, а также чтобы проводить глубокий перформанс аудит с инсайдами по оптимизации.
В качестве базового инструмента отлично себя зарекомендовал Lighthouse, который интегрирован в браузер Chrome и доступен через DevTools. А еще есть сервис PageSpeed Insights поверх, который удобнее для неразработчика, плюс обогащается данными из CrUX. Альтернативой может послужить WebPageTest: он глубже и комплекснее, но вместе с тем - несколько сложнее.
Lighthouse предлагает подробный отчет, там есть:
▪сами метрики,
▪список проблем и их влияние на метрики,
▪рекомендации по устранению проблем (например, “уменьшите размер изображений”)
▪диаграммы загрузки страницы,
▪логи и трассировки.
Отчет еще хорош тем, что его можно скачать в JSON, а потом открыть через Lighthouse Report Viewer, то есть это приятный артефакт для бэклога.
Важно, lighthouse - про лабораторные, а не полевые данные. Раз там нет пользователя, то и метрик взаимодействия пользователя со страницей тоже нет. Но вот что есть:
▪Total Blocking Time (TBT) - вместо INP, про блокировку основного потока. Если значение высокое, то есть вероятность, что и реакция страницы на действия пользователя будет медленной.
▪Speed Index (SI) - измеряет скорость визуального отображения страницы. В отличие от точечных метрик (LCP или FCP), он учитывает постепенное появление контента во время загрузки, тем самым оценивая воспринимаемую пользователем скорость.
Еще там есть общий Performance score, который складывается из основных метрик производительности и одним числом от 0 до 100 показывает насколько все плохо. Компоненты и веса скоринга иногда обновляются, например метрика TTI (Time to Interactive) стала deprecated и отвалилась. Использовать один агрегирующий показатель для быстрой оценки ситуации в тестах - также удобно, как и индекс счастья для RUM.

Lighthouse performance scoring на 2025 год,
тут уже нет TTI
Lighthouse анализирует отдельные страницы, а не сайт целиком. Да и вне зависимости от инструмента, проводить тесты по всем страницам большого сайта - долго и нецелесообразно. Для тестов оптимально выбрать топ-N страниц, которые представляют наиболее важные функции или разделы сайта.
Инструмент имеет открытый исходный код, может запускаться через CLI или программно через Node.js. Это позволяет интегрировать его в уже имеющиеся CI-пайплайны, делая его частью релизного цикла.

Тесты в CI на базе Lighthouse перед деплоем в прод
Помимо запуска на стейджинге, на основе синтетических тестов можно организовать мониторинг и в продакшне, запуская тесты по расписанию, симулируя устройства и поведение пользователей.
Сторонние сервисы (например, SpeedCurve Synthetic Monitoring или Calibre Performance Audit) предлагают свои решения для синтетики, но часто также опираются на репорты и аудиты от Lighthouse. Они могут предоставлять свой SDK для простой настройки и запуска тестов, иметь интеграции в CI, а также свои CLI-инструменты (например, speedcurve-cli). При выборе следует обратить внимание на:
▪Помимо нужных интеграций, богатства API и удобства UX;
▪Поддержка пользовательских сценариев: авторизация, клики на нужные элементы управления.
▪Возможные настройки тестов: тип устройства, скорость сети, геолокация (тесты из разных регионов) и настройки браузера.
▪Поддержка автоматизации: запуски по расписанию, по триггеру из CI, по API или из командной строки.
RUM и синтетические тесты отлично дополняют друг друга. Совместное использование двух подходов позволяет выявлять проблемы производительности, с которыми сталкиваются пользователи на сайте, определять причины этих проблем и получать первые рекомендации по их устранению.
На заметочку, некоторые сервисы умеют сразу и в RUM, и в синтетику - Catchpoint, SpeedCurve или Akamai - что делает их универсальными инструментами.
Собираем все вместе
Итого, метрики для мониторинга сведены к одному показателю в RUM и под скоринг в синтетике, инструментов всего два бесплатных или один универсальный (но платный) и два источника тревоги:
▪Apdex мониторится - алерты про недовольных пользователей
▪Performance score считается - алерты от недовольных тестов на CI
По-хорошему эти алерты будут работать друг на друга. И плохой индекс производительности в полях будет сопровождаться не-зелеными синтетическими тестами на CI.
Если Apdex показывает неудовлетворительное значение, то процедура следующая:
1.Посмотреть на полевые Web Vitals и определить проблему: загрузка, интерактивность или визуальная стабильность.
2.Воспроизвести проблему в синтетических тестах: некоторые метрики Web Vitals измеряются в лаборатории (загрузка и CLS), некоторые (INP) имеют свои предикторы (TBT).
3.Произвести диагностику с помощью имеющихся инструментов, проанализировать возможные причины, изучив вспомогательные метрики.

Работа с метриками слева направо
Если проблему никак не удается воспроизвести в лаборатории, то это почти наверняка связано с большими различиями в окружениях. В тестах мы имеем почти полностью контролируемые условия, которые далеки от реальных: разные устройства, скорости интернета, локации, кэши, фоновые процессы и прочее. Различия неизбежны, но их можно попробовать свести к минимуму, регулярно анализируя своих пользователей и стараясь повторить их условия и поведение в тестах.
Если Apdex стабильно показывает хорошее значение, но Performance scoring в тестах ругается, то также могут быть причиной различия в окружениях. Но вместе с тем, если какую-то проблему удается легко обнаружить, то почему бы не уделить ей внимание, не дожидаясь эффекта на пользователях?
По итогу, работу с метриками можно еще описать через потребителей:
▪Продакт-менеджеры и аналитики наблюдают индекс пользовательского счастья
▪SEO и UX специалисты в своих исследованиях работают с Core Web Vitals
▪Разработчики и тестировщики изучают и чинят проблемы производительности

Потребители метрик снизу вверх (или сверху вниз)
Кому и какие алерты приходят? Вопрос эскалации (или деэскалации). И вопрос желания разбираться в деталях или видеть только общую картину. Как продактам могут быть интересны отдельные метрики, так и разработчики могут участвовать в исследованиях пороговых значений для обеспечения отличного UX.
Строим рабочий процесс
Какими бы понятными ни были метрики, и каким бы полезным и дружелюбным ни был инструмент для мониторинга и тестирования, само по себе оно не заведется или со временем забросится и ляжет в техдолг. Нужно построить эффективный, непрерывный, предсказуемый процесс.
Шаг первый - Определение требований
В качестве метрики используется собираемый с полей Apdex. Пусть среднее наблюдаемое значение будет не меньше, чем:
▪А) 0.75 - коррелирует с рекомендацией от Google про 75ый процентиль;
▪Б) Какое-то прикинутое значение по метрикам Web Vitals в ChUX по сайтам конкурентов.
Важно, что это требование согласовано с интересами как бизнеса, так и инженеров. Все понимают, про что эта единственная метрика и почему она важна.
Шаг второй - Согласование работ
Необходимо четко зафиксировать, кто, что и в какие сроки делает при нарушении требований по метрике. Примеры договоренностей:
▪ЕСЛИ Apdex отстает на 10% в течение месяца, ТО команда разработки берет в следующий квартал задачу на оптимизацию;
▪ЕСЛИ Apdex отстает на 30% в течение недели, ТО команда разработки берет в следующий спринт задачу на устранение проблем производительности.
Не так важно, будет это KPI, SLA или что-то еще. Но без проговоренных ответственных, приоритета задач и выделяемых ресурсов метрика в какой-то момент просто покраснеет.
Шаг третий - Ревизия требований
Время от времени, например раз в год, нужно пересматривать требования.
Во-первых, конкуренты тоже работают над производительностью все это время. Чтобы нивелировать риск отставания, можно периодически посматривать на их метрики хотя бы в CrUX по домену, или настроить синтетические тесты на основные страницы.
Во-вторых, общая рекомендация про 75-ый процентиль - лишь отправная точка, почему не двинуться к 85-ому? Это же еще 10% довольных пользователей!
Наконец, без оглядки на конкурентов и сухие процентили, важно постоянно изучать возможные корреляции между метриками производительности и коэффициентами конверсий довольных пользователей в платящих. И корректировать требования, основываясь на новых гипотезах и знаниях.

Процессные кубики
Кроме того, могли появиться новые метрики (под капотом Apdex и Performance score), актуальные рекомендации и лучшие практики, более удобные и дешевые инструменты. Это требует периодического внимания, хотя бы со стороны инженеров.
Идеальные инструменты, метрики, UX
Какой-никакой процесс запущен! Осталось довести все до блеска.
Lighthouse отлично подходит для первичного анализа. Его рекомендации подскажут, как оптимизировать Critical Rendering Path, изображения, шрифты, кэширование, как уменьшить нагрузку на браузерный поток, как улучшить скорость ответа сервера или как снизить задержки в API. Это хороший старт, но lighthouse не дает, например, детального анализа рендеринга или проблем на сервере. Подбор “идеального” инструмента будет зависеть от специфики отдельно взятого приложения и требований, предъявляемых к качеству его работы. Как специфика, так и требования могут выработаться далеко не сразу и способны видоизменяться со временем.
То же самое касается и самих метрик. Пусть метрики Core Web Vitals и разрабатывались инженерами Google для оценки разных аспектов пользовательского опыта, и они в самом деле здорово подсвечивают основные проблемы. Но их бывает недостаточно! Иногда в список жизненно важных просятся свои кастомные метрики, отвечающие на вопросы конкретных UX решений, продиктованные техническими особенностями приложения или уникальностью целевой аудитории. Тут на помощь приходят браузерные API (например, elementtiming) или сторонние инструменты (например, Container Timing API от Bloomberg). Разработка “идеального” набора метрик пользовательского опыта - задача небыстрая и непростая, но ее решение может значительно улучшить продуктовые показатели.
Иметь метрики производительности - это хорошо для UX. Еще лучше, когда эти метрики становятся частью самого UX. Пусть требования к производительности войдут в общие гайды по разработке пользовательских интерфейсов в компании. Тем более, если используется общая дизайн-система (например, Semrush Design System). В этих гайдах будет описано, через какое время после начала загрузки показать спиннер или прогресс-бар, как сделать скелетон без сдвига контента, какие активные блоки должны быть покрыты кастомными метриками или как себя должны вести ленивые картинки. Если производительность учитывается в пользовательском опыт с самого начала, это шаг в сторону “идеального” UX.

Пользователь понимает, что что-то происходит
Объясняя кавычки, “идеальные” решения существуют разве что в идеальном мире. А разработка ПО - это, как правило, постоянный поиск компромиссов. Тут лучше следовать принципу Парето и помнить: не-идеальный работающий процесс лучше идеального не-работающего.
Тэйк-эвэйс
Топ-5 ключевых (жизненно важных) мыслей, которые хочется оставить напоследок:
1.Web Performance - это про пользовательский опыт, а не про технические метрики. А хороший Web Performance может стать одним из конкурентных преимуществ.
2.Так как это про пользователей, то и мониторинг стоит строить на пользовательских данных, в реальных условиях.
3.Синтетические тесты помогут предупреждать проблемы, а также могут давать детальные инсайды по оптимизациям.
4.Метрик не так уж и много. Инструменты вполне доступные.
5.Мониторинг - это непрерывный процесс. И заинтересованы в этом процессе - и бизнес, и инженеры.
Постскриптум, Web Performance - это правда важно и оно того стоит.